2 July 2026Answer-engine optimisation (AEO)
A growing number of companies are starting to track their brand visibility on AI chat platforms. They're running prompts through AI models, counting how often their brand gets mentioned, and building reports off the results.
AI brand visibility tracking isn't like social listening or SEO monitoring. The outputs are sensitive to hidden variables that many marketers have never had to think about. Here are seven things worth knowing before you trust the numbers.
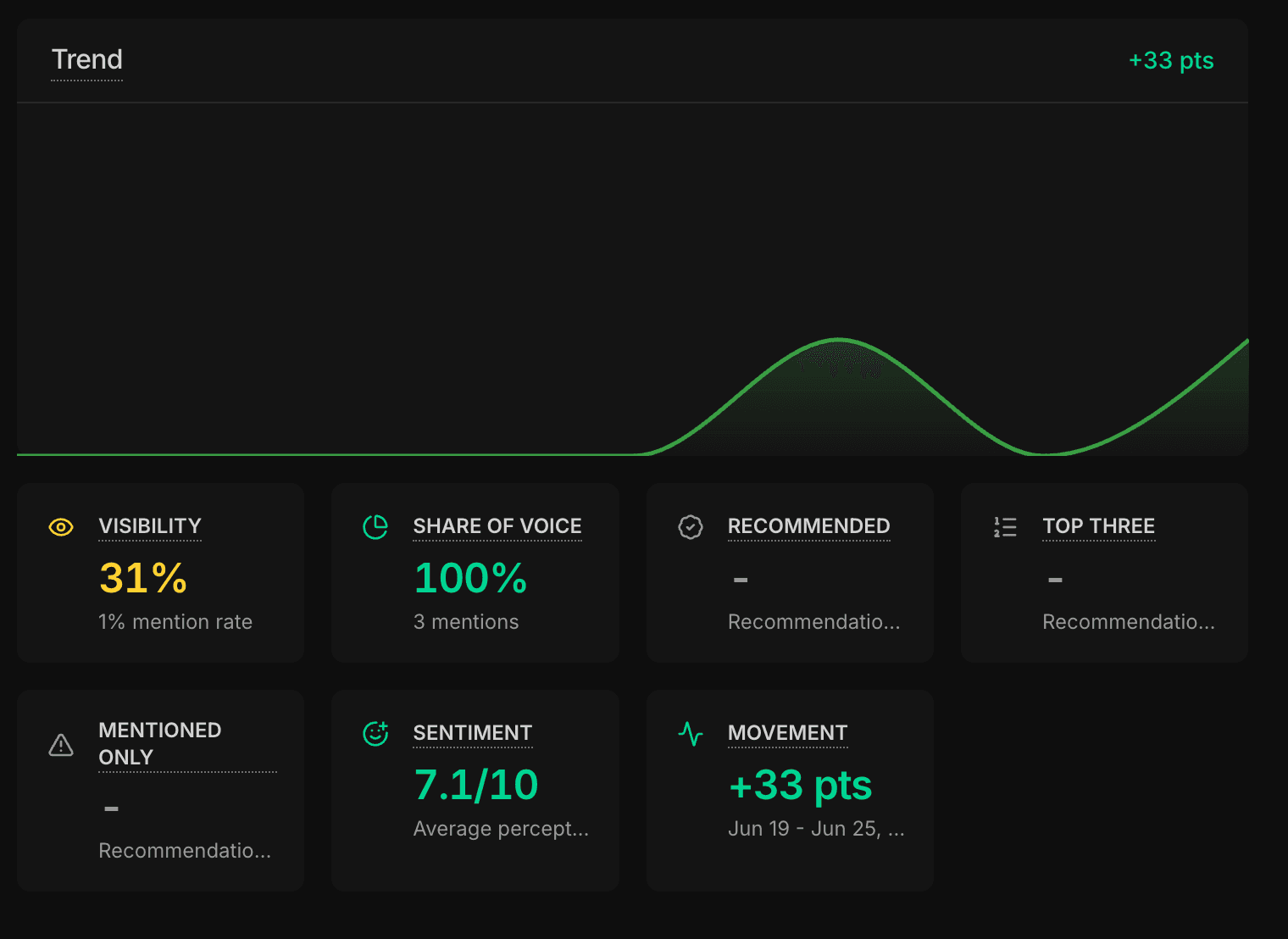
The most common approach is simple: run a batch of prompts, count how many times your brand appears, and report a percentage. Five mentions out of 100 prompts? That's 5% visibility. Job done.
Except it's not. Where your brand appears in a response matters just as much as whether it appears at all. Being mentioned first, as the recommended option, is very different from being listed last as an afterthought. And being described as "the industry leader" tells a different story from being called "a budget alternative."
There are really three things to measure. How often your brand is mentioned (frequency). Where it sits in the response (position). And how it's described (framing). Frequency alone is the shallowest of the three. Position and framing are far more predictive of whether an AI recommendation actually influences a buying decision.
Every AI model has a setting called temperature. It controls how predictable or creative the output is. A low temperature means the model plays it safe and gives the most likely answer. A higher temperature means it explores more, surfacing less obvious options.
This has a direct impact on brand visibility. At low temperature, dominant incumbents tend to appear over and over again. Raise the temperature and you'll see more niche and challenger brands enter the mix.
If you don't know what temperature was used in your tracking, you don't really know what you're measuring. Worse, it's easy to accidentally pick settings that flatter your brand or undercount your competitors. For reliable results, you need to fix the temperature and keep it consistent across every test run.
Some AI models answer purely from what they learned during training. Others search the web in real time before responding. These are fundamentally different scenarios, and they measure fundamentally different things.
When web search is off, you're measuring what the AI "knows" about your brand from its training data. Think of it as embedded mindshare. When web search is on, you're measuring something closer to SEO rankings filtered through an AI layer. The brands that show up are the ones with strong web presence, high domain authority, and content that ranks well in traditional search.
Both are useful metrics. But they answer different questions. And if you're comparing results across models without controlling for whether web search was active, your comparison doesn't hold up. One model might seem to favour your competitor simply because it searched the web while the other didn't.
When marketers write test prompts, they tend to phrase them the way they talk about their own category. Something like "What's the leading enterprise SaaS solution for customer relationship management?"
That's not how real people ask. A small business owner is far more likely to type "what's a good CRM for my team of 10?" or "is HubSpot worth it?" Those different phrasings can produce completely different brand recommendations.
If your prompt set doesn't reflect real consumer language, with all its variation in sophistication, budget sensitivity, urgency, and specificity, you're measuring your own assumptions about how people search. Not how they actually search. Good tracking requires prompts that span the full range of how real buyers talk about your category.
Marketers are used to Google rankings being relatively stable. You search something today and tomorrow, you get more or less the same results. AI models don't work that way. Run the same prompt twice and you might get different brands mentioned each time. I.e., AI models are non-deterministic.
This means a small test of 10 or 20 prompts can be wildly unreliable. You might see your brand mentioned in 30% of responses one day and 10% the next. Without running enough prompts (hundreds, not dozens) and checking how stable your results are across repeated runs, you can't tell whether you're looking at a real signal or just noise.
Before drawing any conclusions, run the same set of prompts multiple times and measure how much the results vary. If brand mentions swing by more than 10 to 15% between identical runs, your setup may not be stable enough to trust.
It's tempting to test your brand across ChatGPT, Gemini, Claude, and Perplexity, then declare which one is "best" for your brand. But a fair comparison requires holding everything else constant. Same prompts. Same temperature. Same system instructions. Same web search settings.
There are also subtler traps. Different models produce different response lengths. A model that writes longer answers will naturally mention more brands, which inflates its visibility scores. If you don't normalise for response length (measuring brand mentions as a proportion of total brands mentioned, rather than raw counts) you'll draw the wrong conclusions.
Model comparisons can be genuinely valuable. They can reveal which platforms are more likely to surface your brand organically. But only if the comparison is controlled. Otherwise you're just measuring the differences in your test setup.
This one is subtle, but important. If you use GPT to generate a set of realistic consumer prompts and then test GPT's responses to those prompts, you've created a feedback loop. The model's own biases shaped the questions it's now answering.
It's a form of contamination that doesn't exist in traditional marketing measurement. The fix is straightforward. Generate your prompts with one model (or better yet, base them on real search data and customer research). Then freeze that prompt set. Then test it across whatever models you want to evaluate. Keeping prompt generation and testing separate is one of the simplest things you can do to make your results more trustworthy.
AI-powered discovery is becoming a genuine channel for how people find products and services. Tracking your brand's visibility in that channel is a smart move. But the measurement is more nuanced than most marketing teams realise. Hidden settings, prompt design, web search, sample size, and model differences all influence the results in ways that traditional digital marketing doesn't prepare you for.
The good news? None of this is impossibly complex. It just requires a structured approach and an awareness of what can go wrong. Get the methodology right and you'll have a genuinely useful view of how AI sees your brand. Get it wrong and you'll make confident decisions based on numbers that don't mean what you think they mean.
Want to understand how your brand shows up in AI? We've built our own AI brand visibility tool - you can get a taste of the insights it offers by running a free AI brand visibility audit. Try it today, or get in touch and we can help you design rigorous visibility tracking across models and categories.
Our team is here to help. Get in touch with us to discuss your specific needs.